SQL Server2005扩展函数已经不是一件什么新鲜的事了,但是我看网上的大部分都是说聚合函数,例子也比较浅,那么这里就讲讲我运用扩展函数来优化数据库性能的例子,希望和大家一起分享这个经验。如果你还不知道什么是SQLCLR,那么你可以参考:SQL Server扩展函数的基本概念。
需求说明
大家在使用SQL Server开发的时候一定会遇到这样的需求,那就是通过Table_Name1表的两个字段Column1、Column2来查询在Table_Name2表中符合这两个条件的记录,并返回Table_Name2中的字段Column3,面对这样的需求,你也许会说使用表连接就可以了,对的,没错,我也是这样想的,但是有的时候往往要面对不同的突发情况,那就是并不是一定会Column1与Column2是全匹配的查询,可能中间还需要一些逻辑的处理,比如字符串的截取后再匹配等等。
这个时候我们通常会在SQL Server中写一个函数,这个函数接收两个参数:Column1、Column2,函数体里面做一些逻辑处理,在通过处理好的参数去查询Table_Name2表,并返回相应的值。很好,那下面我们来计算下图中数据的查询情况。假设表1的数据有50W,表2的数据有4W,在表2没有索引的条件下,查询的复杂度就有50W*4W了,两个表都需要做全表扫描,表2的全表扫描就会达到50W次。
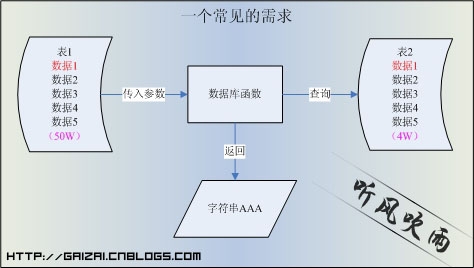
(图1:需求说明)
优化1:这一个优化,每个开发人员都知道,那就是对表2的两个查询字段分别建立索引。这样的优化和之前相比,性能将会提高N个等级。
优化2:这第二个优化方法是使用SQL Server的复合索引,在表2上创建一个复合索引,这个符合索引包括需要查询的两个字段,其实就是把两个字段的内容生成一个索引,其中索引包含了两个索引的排序。
优化3:这第三个优化方法是使用SQL Server2005之后版本才有的索引-包含性索引(Include),就是在优化2的基础上,把需要返回的字段也一起放入到索引中,这样的查询就只需要查询索引就够了,不需要再读取数据页了,减少磁盘的IO消耗。不过这个方法也不是万能,因为有时可能返回的字段会比较多,有时几个字段加起来的长度有可能超出了900个字符(索引大小范围),如果想了解可以进入:SQL Server 索引中include的魅力(具有包含性列的索引)
优化4:在不考虑一些分区、分表、分到不同的磁盘等优化方式的情况下,我们是否还能进一步优化我们的查询呢?这就是这篇文章想要告诉你的,因为我们的回答是:有的。那就是通过SQLCLR的UDT,把表2的数据一次性加载到内存,那么在进行表1查询的时候,我们不需要通过B+树来查询数据了,直接到内存中查询,这样之所以快是因为操作内存要比操作磁盘要快得多。这其中会有些局限性和缺点,具体见下面的缺点描述。
设计思路
1、去数据库中把表2读取出来,并放到private static readonly IDictionary<string, string> resultCollectionDic的静态变量中。在数据库服务启动的时候是会初始化2、SQLCLR函数的,所以在启数据库服务的时候,也一起把表2的数据保存到了内存当中了。
3、上面的查询中包括了两个字段Column1、Column2和一个返回字段Column3,那么我们如何把这些数据保存到IDictionary字典当中呢?我的做法就是把Column1、Column2的中间加一个字符“+”,把这个字符串作为Key值,把Column3这个返回值做为Value,这样就解决了多个And的查询的问题。这个会有些局限性,具体可以见下面的缺点描述。
在函数FunctionImsi2HLR2中传进的两个字符后,就要进行上面的拼凑方式来拼凑Key值,再到IDictionary中查询。
测试结果
测试数据:表2有4.6732万条记录,表1有54.2524万条记录。
经过测试:
1、优化1方法(单独索引)的时间是106秒
2、优化3方法(包含性索引)的时间是45秒
3、优化4方法(扩展函数)的时间是33秒
代码
| 以下为引用的内容:
using System; |
调用方式对比
|
以下为引用的内容: --1:这个是在NP和NS字段中分别建立索引 |
优点
1、性能上的比较(这里的>是表示时间的长短,时间越小,性能越优):每个列有单独的索引>使用Include的包含索引>扩展函数
把表里面的记录放到内存上,直接去内存上查询,不需要使用到B+树来查询数据。当你的内存足够大或者空闲,并且使用到这个表的次数很多,而且更新不频繁,那就可以考虑这样的优化方案。
2、如果需要面对一些比较复杂的逻辑处理,也许SQL是没有办法做到,即使做到了,那么SQL代码的阅读和维护会比较困难,其实这个既是优点又是缺点,下面的缺点中有提到。
封装代码,加强代码安全。
缺点
1、有一定的局限性,当有多个AND条件一起查询或者几个键通过上面的方法加起来的字符串不唯一,那么就没有办法像上面IDictionary<string, string>的方法来使用key了,但是也不是没有办法的,其实办法就是IList,把唯一的值作为key,再构造一个实体作为key的value。
2、如果表更新了,需要重新注册函数,因为程序已经把整个表加载到内存了;如果不重新注册函数,那么就需要数据库重启服务了,因为那个程序集是在服务启动的时候就初始化了。
3、针对上面第二个缺点,也是有办法解决的,那就是在表中做一个触发器,当有Insert、Update、Delete等操作就调用一个重新注册的存储过程就可以了。
4、如果里面的逻辑处理比较复杂,那么更新逻辑所带来的部署、维护成本比较大,因为如果是写成函数或者是建立包含性索引可能会更好维护。
疑问
1、在SQL Server中,对一个包含性索引的疑问:比如有一个int类型的字段和一个nvarchar的字段,int字段的重复率比较大,而nvarchar的重复率比较少,我之前是根据重复率来确认谁放前面的,但是int与nvarchar的匹配效率是不一样的,int只要匹配一次,而nvarchar需要匹配跟字符串长度一样多的次数,那么应该如何把谁放到前面呢?
2、数据库中可以把90%的查询都归结为1:完全匹配,2:前缀匹配。对应解决方案是:1:可采用bloom-filter扩展函数进行高速匹配,2:可采用改进的哈夫曼树。如何做这方面的方案呢?
总结
虽然这样的方式比较难在现实的运用中被使用,因为有很多局限性和缺点,但是我写这篇文章的初衷就是想让大家知道在特殊的情况下,还有这样一种优化的方法可以使用。
类别:数据库技术 来源:本站原创 作者:hpping 日期:2010-05-27 11:52
上一条:通过索引优化含ORDER BY的MySQL语句
下一条:超越批量处理与MapReduce:如何让Hadoop走得更远
软件产品
- HTCMS 4.0.5
专业的旅游营销及内容管理系统 - HDCMS 2.0.8
HDUT内容管理系统,为您提供专业建站CMS,原来专业站也不过如此