如果你曾经开发过内容聚合类网站的话,使用程序动态整合来自不同页面或者网站内容的功能肯定对于你来说非常熟悉。通常使用Java的话,我们都会使用到一些HTML的解析,例如,httpparser,最早的整合搜索就是使用httpparser来抓取Google和Baidu的搜索结果,并且整合呈现给搜索用户,这也就是GBin1域名的由来。
那么今天呢,我们介绍另外一个超棒的Java的HTML解析器 - jsoup,这个类库可以帮助大家实时的处理HTML。提供了非常方便的API来提取和处理数据,最重要的它使用类似jQuery的语法来处理DOM,CSS等,如果你使用过jQuery的话,就知道它处理DOM的强大方便之处。
主要特性
jsoup实现了WHATWG HTML5 的标准,和现代浏览器解析DOM的方式一样。主要功能:
1.可以从URL,文件或者字符串中抓取和解析HTML
2.使用DOM的查询和CSS选择器来查找和解压数据
3.可以处理HTML的属性,元素和文本
4.帮助用户处理递交的内容,并且防止XSS攻击
5.输出干净的HTML
基本上jsoup可以帮助你处理各种的HTML问题,并且帮助你验证非法的tag,创建一个干净的DOM树。
实现一个抓取功能
这里我们将实现一个简单的抓取功能,你只需要指定url,并且指定你需要抓取的特定元素,例如,ID或者class。后台我们将使用jsoup抓取,前台使用jQuery美化生成结果。
大家需要注意以下几点:
1.<a>的相对路径问题:在你抓取的页面中的链接有可能使用相对路径,你需要处理成绝对路径,否则你在本地服务器上无法正常打开链接
2.<img> 的相对路径问题:同上,你同样也需要处理转化
3.<img>的尺寸问题:如果你抓取的图片特别大,你需要使用代码转换成本地样式,这个你也可以选择使用jQuery在前台处理
下载jsoup的jar包后,请加入你的classpath路径,如果你使用jsp,请加入web应用WEB-INF的lib目录中。
Java相关代码如下:
以上代码,我们定义jsoup使用一个url来获取HTML,这里使用http://www.gbin1.com/portfolio/lastest.html,这个页面中列出了最近发布的文章。如果你查看此页面源代码,可以看到,每一个文章都在.includeitem这个class中,因此,我们这里使用doc.select方法来选择对应的class。
注意我们这里调用timeout(0),这意味着持续的请求url,缺省为2000。即2秒后超时。大家可以看到这里使用了类似jQuery的链状调用,非常方便。
以上代码中,我们处理每一个查询到的includeitem元素。查找“a”和“img”,将其中的href元素值修改为绝对路径。
以上代码将会得到对应链接的绝对路径,其中属性为abs:href。同理,可以得到图片绝对路径abs:src。
代码运行后,我们可以看到修改完的代码, 将他们放置于li中。
接下来我们开发控制抓取的JavaScript页面:
在这个页面的实现中,我们使用setInterval方法间隔指定的时间使用ajax调用以上Java开发的代码,基本代码如下:
以上代码非常简单,我们使用jQuery的load方法来调用siteproxy.jsp,然后取得siteproxy.jsp生成页面中的#result元素,即抓取内容。
为了能够让代码指定间隔时间运行抓取,我们将方法放入setinterval中,如下:
通过以上方法,我们可以在用户触发抓取后,每隔指定时间触发抓取动作。
完整js代码如下:
将以上jsp和html文件部署以后,将可以看到如下界面:
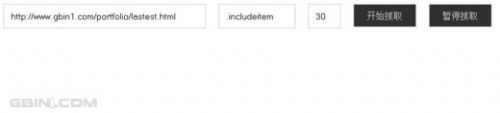
我们需要设置抓取的url和页面元素,这里缺省是http://www.gbin1.com/portfolio/lastest.html ,元素为.includeitem,点击开始抓取,可以看到应用抓取如下内容:
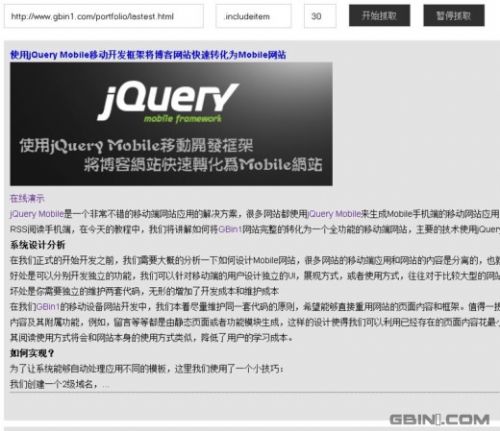
注意这里缺省间隔时间为30秒,30秒后会自动重新抓取内容。
你可以尝试抓取weibo.com, 元素.itemt, 间隔时间10秒,能得到如下内容:
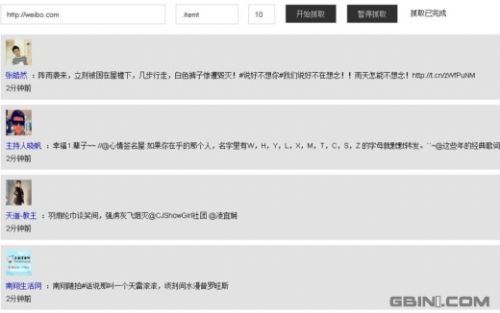
你可以看到和微博首页的自动刷新内容一样。
大家可以把这个工具当做页面重复刷新工具,可以帮助你监控某个网站某个部分内容,当然,你也可以使用它来动态刷新你的网站,提高你的alexa排名。
希望大家喜欢这个工具应用,如果你有任何建议和问题,请给我们留言!谢谢!
类别:JavaScript技术 来源:互联网 作者:hpping 日期:2012-07-26 11:02
上一条:JavaScript解析:让搜索引擎看到更真实的网页
下一条:对现代开发来说,JavaScript是一种垃圾语言
软件产品
- HTCMS 4.0.5
专业的旅游营销及内容管理系统 - HDCMS 2.0.8
HDUT内容管理系统,为您提供专业建站CMS,原来专业站也不过如此